

{kind=link}
Ho ricevuto una domanda relativa alle dimensione dei file (in particolare
divina.txt che costituiva l’input
per un esercizio assegnato nella Lezione 04).
Approfitto della domanda per spiegare alcuni concetti di base legati all’encoding di un file di testo. Infine, chiarisco alcuni punti riguardanti i caratteri “terminatori di linea” (caratteri “a capo”, o end-of-line (EOL)) su sistemi Unix-like, anche detti sistemi *nix, come le distribuzioni Linux e Mac OS X e i sistemi DOS/Windows.
Come si calcola la dimensione di un testo in Java?
La risposta in realtà è “dipende”. Ciò è dovuto al fatto che si può intendere la “dimensione di un (file di) testo” in modi diversi.
1. Dimensione di un file di testo come numero di bytes
In Java, l’oggetto File possiede il metodo File.length() che ritorna la
lunghezza in byte del file da esso rappresentato. Questa è la stessa dimensione
che compare anche nel filesystem (per esempio controllando con il tasto destro
le “Proprietà” del file).
Utilizzando il terminale (o linea di comando), possiamo ottenere le stesse informazioni rispetto ai file contenuti nelle soluzioni agli esercizi della lezione 04.
- (Sistemi *nix): comando
ls -l
$ ls -l
total 64
drwxrwxr-x 2 cristian cristian 4096 nov 8 19:24 bin
-rw-rw-r-- 1 cristian cristian 5065 nov 8 19:48 divina.txt
-rw-rw-r-- 1 cristian cristian 5201 dic 9 23:40 divina_win.txt
-rw-rw-r-- 1 cristian cristian 74 nov 8 19:40 esercizio01.txt
-rw-rw-r-- 1 cristian cristian 20 dic 9 23:40 risultati.txt
drwxrwxr-x 2 cristian cristian 4096 nov 8 19:24 srcLa quarta colonna riporta la lunghezza dei file in bytes, per
divina.txt sono 5065 bytes. Notate che le cartelle bin e src occupano
ciascuna 4096 bytes (4 KB).
- (DOS/Windows): comando
dir
C:\Users\cristian\infomat\SoluzioniLezione04> dir
Directory: C:\Users\IEUser\Desktop\infomat\SoluzioniLezione04
Mode LastWriteTime Length Name
---- ------------- ------ ----
d---- 11/8/2015 7:58 PM bin
d---- 11/8/2015 7:58 PM src
----- 11/8/2015 7:58 PM 295 .classpath
----- 11/8/2015 7:58 PM 377 .project
----- 11/8/2015 7:58 PM 5065 divina.txt
----- 11/8/2015 7:58 PM 5201 divina_win.txt
----- 11/8/2015 7:58 PM 74 esercizio01.txt
----- 11/8/2015 7:58 PM 55 risultati.txt
La terza colonna riporta la lunghezza del file (in bytes), anche in questo caso
divina.txt è un file lungo 5065 bytes.
2. Dimensione di un file di testo come numero di caratteri
Lo scopo dell’esercizio assegnato durante la lezione 4 era contare il numero di
vocali presenti in divina.txt: ho modificato la soluzione
(file SoluzioneDivina.java) per contare il numero di caratteri totali.
Eseguendo il programma si ottiene:
File length: 5201. == Statistiche == num. a: 422. num. e: 429. num. i: 386. num. o: 323. num. u: 150. totale vocali: 1710. totale caratteri: 4849.
Il numero totale di caratteri (esclusi gli “a capo”) è quindi 4849.
Caratteri non ASCII e encoding
Come detto a lezione, per salvare un file di testo su disco è necessario procedere alla sua “traduzione” (o encoding) in una data codifica di caratteri (o charset).
ASCII
Storicamente, il primo sistema di codifica di caratteri è stato il codice Morse inventato nel 1837 per trasmettere messaggi via telegrafo.
Nel codice morse ogni carattere viene rappresentato con una sequenza di simboli che possono essere: punto (•), linea (—), intervallo breve (tra ogni lettera), intervallo medio (tra parole) e intervallo lungo (tra frasi).
In questo modo, si può usare una tabella di conversione
e “tradurre” ogni lettera in una data sequenza. Per esempio, la lettera S viene
codificata da tre punti consecutivi (separati da spazi brevi): • • • e la
lettera O viene tradotta da tre linee consecutive: — — —.
Quindi il famoso messaggio di aiuto “SOS” si traduce con la sequenza (molto
facile da ricordare): “tre punti, tre linee, tre punti”: • • • — — — • • •.
In ambito informatico, negli anni ‘60 del XX secolo, viene ideato il codice ASCII (acronimo di American Standard Code for Information Interchange, Codice Standard Americano per lo Scambio di Informazioni).
L’ASCII è un codice a 7 bit che associa un carattere (una lettera, un numero,
un segno di punteggiatura) ad ogni numero decimale tra 0 e 127 (ovvero tra
i numeri binari 0000000 e 1111111). Quindi per esempio il carattere “ “
(spazio) è rappresentato dal numero 32, la lettera “A” dal numero 65, la lettera
“a” dal numero 97.
Qui di seguito è presentata una tabella compatta della conversione tra codice
ASCII (in valori decimali) e lettere da 30 (RS, record separator) a 127 (DEL).
I valori minori di 30 sono utilizzati per inviare codici speciali come per
esempio il codice 7 (BEL) che produce un suono, o l’11 per la tabulazione
(\t).
30 40 50 60 70 80 90 100 110 120
---------------------------------
0: RS ( 2 < F P Z d n x
1: US ) 3 = G Q [ e o y
2: * 4 > H R \ f p z
3: ! + 5 ? I S ] g q {
4: " , 6 @ J T ^ h r |
5: # - 7 A K U _ i s }
6: $ . 8 B L V ` j t ~
7: % / 9 C M W a k u DEL
8: & 0 : D N X b l v
9: ´ 1 ; E O Y c m w
--
From the Linux man page: man ascii
Essendo un codice a 7 bit, ogni carattere del codice ASCII poteva essere salvato in un byte (8 bit) che è l’unità di base gestita dai processori dei computer dell’epoca (e attuali), inoltre la maggioranza delle codifiche contengono l’ASCII come sottoinsieme nei primi 7 bit1.
Possiamo crare un file di testo (con un programma come
GEdit su Linux,
TextEdit su Mac o
Notepad su Windows)
e salvarlo come ascii.txt con il contenuto seguente:
abcd↵
(il simbolo ↵ indica “invio”).
Salvando il file, avrà una dimensione di 6 bytes (su sistemi DOS/Windows) o 5 bytes (su sistemi *nix).
Il file verrà salvato e codificato usando la codifica predefinita di sistema, che dipende dalle impostazioni della lingua (locale, in inglese)2. Su sistemi che usano lingue occidentali la codifica è solitamente l’ISO-8859-1 oppure UTF-8, allora ogni carattere ha esattamente la dimensione di un byte, quindi in questo caso la dimensione del file in bytes equivarrà al numero di caratteri.
Tutti i caratteri sono codificabili in ASCII, quindi la dimensione è data da un byte per ciascuna lettera e 2 bytes (su Windows) o 1 byte (su *nix) per il terminatore di riga (il carattere di “a capo”).la spiegazione di questa differenza è il tema della prossima sezione.
Oltre ASCII
Se si usano caratteri non-ASCII questa equivalenza non è più vera. In generale, possiamo dire che per rappresentare caratteri non-ASCII è necessario più di un byte.
Per esempio creiamo un file chiamato non-ascii.txt
con il seguente contenuto:
abcdè↵
Salvando il file, avrà una dimensione di 7 bytes (su sistemi DOS/Windows) o 8 bytes (su sistemi *nix). Quindi l’encoding utilizzato per rappresentare il carattere “e con accento grave” sono necessari 2 bytes.
Quindi, quando si hanno caratteri non ASCII la dimensione in byte non equivale necessariamente al numero di caratteri.
Le difficoltà legate alla gestione dei file di testo sono dovute al fatto che non è possibile conoscere a priori, ovvero senza leggere il file, qual è l’encoding utilizzato per rappresentare i caratteri. A questo si aggiunge il fatto che nella rappresentazione dell’ASCII a 8 bit di fatto è rimasto libero un bit (pari a 128 combinazioni aggiuntive possibili) che è stato utilizzato negli anni nei modi più svariati creando decine di encoding diversi (e incompatibili tra loro).
Gli encoding esistenti sono moltissimi: una lista è disponibile sul sito della IANA, mentre su Wikipedia la lista di quelli che sono indicati come “encoding più comuni” sono oltre 60.
Questa situazione ha, storicamente, creato molte difficoltà ai programmatori e svariati
problemi per l’internazionalizzazione e la localizzazione
dei software3. Questa situazione creava problemi anche per lo scambio di file:
un file creato su un sistema con un dato encoding, passato su un altro sistema veniva
decodificato in maniera errata. Per esempio4, su alcuni PC il codice carattere 130
veniva visualizzato come é, ma sui computer venduti in Israele veniva visualizzato
come la lettera dell’alfabeto ebraico Gimel (ג), e quindi la parola résumé
scritta in un documento con un locale impostato all’inglese americano veniva
visualizzata come rגsumג.
Per altre lingue, come per esempio il russo, erano (e sono tuttora) disponibili
svariati encoding diversi e quindi non era possibile scambiarsi documenti in russo
in modo affidabile.
Tutti questi encoding5, che facevano uso delle combinazioni date dall’ottavo bit (quindi i numeri da 128 a 255), furono riuniti in uno standard ANSI noto come ISO 8859-1 nel 1985. In questo standard tutti i codici inferiori a 128 erano identici (e coincidevano sostanzialmente con l’ASCII) mentre venivano descritti i diversi modi per gestire i codici superiori a 128, che dipendevano dall’impostazione del locale del sistema. Questi diversi sistemi sono stati chiamati “code pages”. Per esempio, in Israele i sistemi DOS usavano la code page numero 862, mentre per il greco si usava la code page 7376.
Il problema divenne ingestibile quando con l’arrivo di internet divenne molto semplice scambiarsi file che erano stati scritti su sistemi che usavano encoding diversi.
Per questo motivo fu inventato l’encoding Unicode, che non è un encoding di per sè, ma un sistema di rappresentare i caratteri. In Unicode, ogni carattere viene rappresentato da un numero detto code point che a sua volta può essere codificato con encoding diversi.
Un carattere unicode è rappresentato come un numero preceduto da “U+” pertanto la lettera Ḁ è il code point U+1E00 e rappresenta la “Lettera latina maiuscola A con un anello sottostante”.
In particolare, Unicode può essere codificato in UTF-8 (Unicode Transformation Format, 8 bit). UTF-8 è un encoding a lunghezza variabile (variable length encoding) per cui alcuni caratteri sono rappresentati usando un singolo byte, altri ne utilizzano due (o più, fino a 4). UTF-8 si è diffuso moltissimo negli ultimi anni ed è ampiamente utilizzato nel Web.
{kind=link}
Riprendendo l’esempio precendemte, la lettera Ḁ, ovvero code point U+1E00,
viene codificata in UTF-8 con la sequenza di tre bit 11100001 10111000 10000000.
Chi volesse ulteriori informazioni su Unicode, così come chiunque abbia in mente di scrivere un programma che gestisce stringhe di testo è invitato a leggere i due post linkati nella prossima sezione.
In conclusione (per quanto riguarda l’encoding)
Possiamo fare alcuni calcoli relativi al file divina.txt:
-
è possibile convertire il contenuto nel file in soli caratteri ASCII. Questo vuol dire, per esempio, convertire il carattere
è → e,à → a, ecc.. Questo processo si chiama traslitterazione. sBisogna fare attenzione al fatto che alcuni caratteri come le virgolette basse (ovvero«e») vengono convertiti in due caratteri ovvero« → <<e» → >>. -
Se alla dimensione del file convertito in ASCII (5001 byte) si sottrae il numero di righe (136) e si tiene conto del fatto che ci sono 8 caratteri
«e altrettanti»che sono convertiti in due caratteri si ottiene: \(5001 - 136 - 8 - 8 = 4849\) che è esattamente lo stesso conteggio che si ottiene contando i singoli caratteri (esclusi i caratteri da a capo).
In conclusione, non ha senso gestire una stringa senza conoscere l’encoding che sta utilizzando. Qualsiasi editor di testo moderno e non minimale dovrebbe permettervi di scegliere qual è l’encoding da utilizzare per salvare il vostro file di testo. UTF-8 è una buona scelta.
Per chi volesse approfondire l’argomento consiglio di leggere questi due post, in inglese:
-
“The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) di Joel Spolsky, uno dei fondatori del sito di domande & risposte Stack Overflow.
-
“What every programmer absolutely, positively needs to know about encodings and character sets to work with text” di David C. Zentgraf.
Caratteri terminatori di linea (o “a capo”)
Rimane da risolvere un problema: come mai salvando lo “stesso” file creato con
GEdit o con Notepad ha delle dimensioni diverse (per esempio 5 o 6 bytes nel
caso del file ascii.txt):
$ ls -l
-rw-rw-r-- 1 cristian cristian 5 dic 14 11:50 ascii.txt
-rw-rw-r-- 1 cristian cristian 6 dic 14 11:49 ascii_win.txt
-rw-rw-r-- 1 cristian cristian 7 dic 14 13:08 non-ascii.txt
-rw-rw-r-- 1 cristian cristian 8 dic 14 13:07 non-ascii_win.txtUn punto che vale la pena chiarire immediatamente è che la differenza non è dovuta all’encoding. entrambi i file sono salvati con encoding UTF-8.
La differenza sta nel carattere di “a capo” (newline, line break, in inglese, oppure carattere end-of-line / EOL).
Il carattere di ritorno a capo è un carattere speciale usato per gestire la fine di una riga di testo (e quindi non un vero e proprio carattere visibile sullo schermo).
Piattaforme hardware e sistemi operativi diversi possono rappresentare il carattere di ritorno a capo in modi diversi. Come abbiamo visto per l’encoding, questo costituisce un problema quando è necessario lo scambio di dati tra sistemi che usano rappresentazioni differenti.
Nell’ASCII esistono due caratteri che possono essere usati (da soli o in combinazione), per rappresentare il ritorno a capo:
-
il carattere numero 10 detto LF (line feed) o anche
\n(new line) -
il carattere numero 13 detto CR (carriage return) o anche
\r
Questi due caratteri indicano rispettivamente una “nuova linea” e il “ritorno del carrello”. Per chi di voi abbia mai utilizzato una macchina da scrivere questi due caratteri corrispondevano a due operazioni diverse (solitamente consecutive) fatte sulla “leva del ritorno a carrello”: spingendo la leva si faceva girare il rullo che alzava il foglio, rendendo disponibile una nuova riga (line feed), al termine della corsa della leva si continuava a spingere sulla stessa per fare tornare il carrello alla posizione iniziale (carriage return).
 |
{kind=link}
Esistono quindi tre modi per indicare una terminazione di linea:
-
LF (
\n): usata da sistemi Unix e sistemi Unix-like (GNU/Linux e Mac OS X, tra gli altri); -
CR+LF (
\r\n): usata da MS-DOS e Microsoft Windows; -
CR (
\r): Macchine Commodore, famiglia Apple (Mac OS fino alla versione 9 inclusa e per questo anche noto come EOL “Mac classico”)
Pertanto il contenuto del file ascii.txt
è più precisamente il seguente:
abcd\n
Invece, lo stesso file creato con gli EOL Windows (ascii_win.txt)
avrebbe il seguente contenuto:
abcd\r\n
Possiamo visualizzare anche con i seguenti comandi da terminale che elencano i caratteri presenti rispettivamente in
ascii.txt e ascii_win.txt:
$ cat ascii.txt | od -cv -An
a b c d \n
$ cat ascii_win.txt | od -cv -An
a b c d \r \nDato che entrambi i file sono salvati con la codifica UTF-8 e constano solo di
caratteri ASCII ogni carattere può essere codificato in un byte e quindi le dimensioni
dei due file sono rispettivamente 5 bytes per ascii.txt e 6 bytes per ascii_win.txt
Un modo per distinguere tra le due tipologie di terminatori è usare il comando
file disponibile sulle distribuzioni Unix e anche su Windows (come installare
questi strumenti utili sarà oggetto di un altro post). Il comando file cerca
di inferire alcune informazioni rispetto al file specificato come argomento:
$ file ascii.txt
ascii.txt: ASCII text
$ file ascii_win.txt
ascii_win.txt: ASCII text, with CRLF line terminatorsCome si può vedere nel caso di ascii_win.txt viene indicato che il file usa i
terminatori CR+LF.
Convertire da terminatori di linea *nix a DOS/Windows
Esistono diversi modi per convertire i terminatori di linea dal formato *nix a quello DOS/Windows e viceversa.
Eclipse
Innanzitutto in Eclipse è possibile
cambiare i terminatori di linea
per il file corrente dal menu File > Convert Line Delimiters To7.
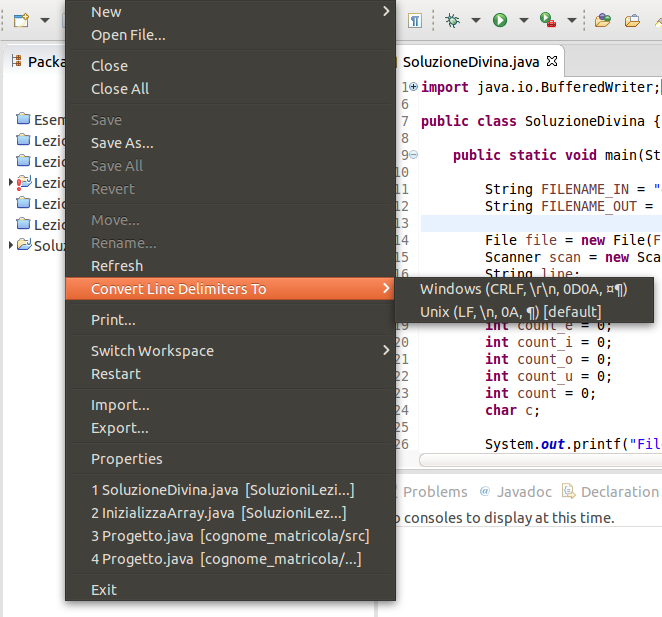 |
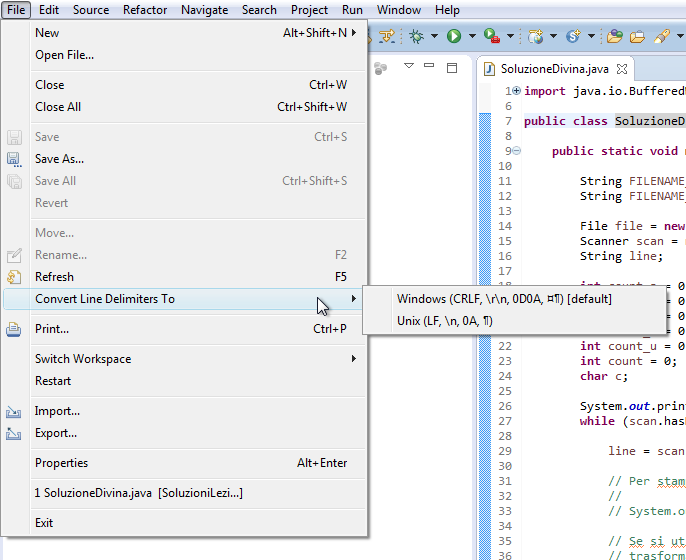 |
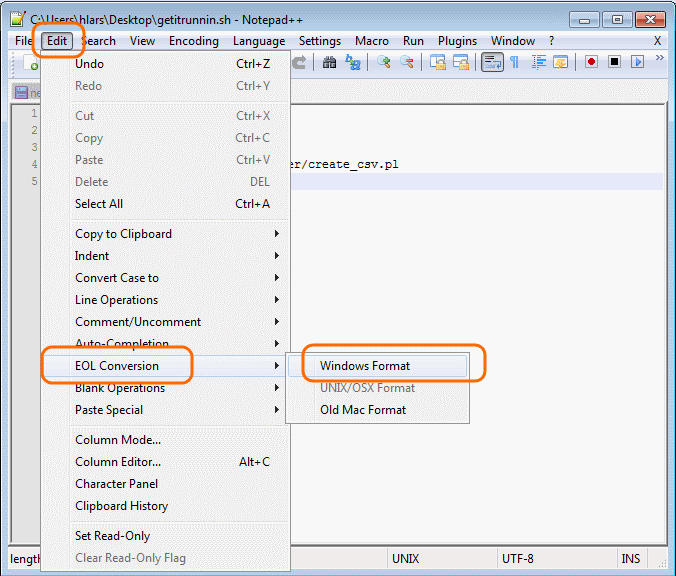
Altri editor di testo
In generare gli editor di testo moderni, come per esempio GEdit su Linux, TextEdit su Mac o Notepad++ su Windows permettono di gestire sia l’encoding da utilizzare che i terminatori di riga.
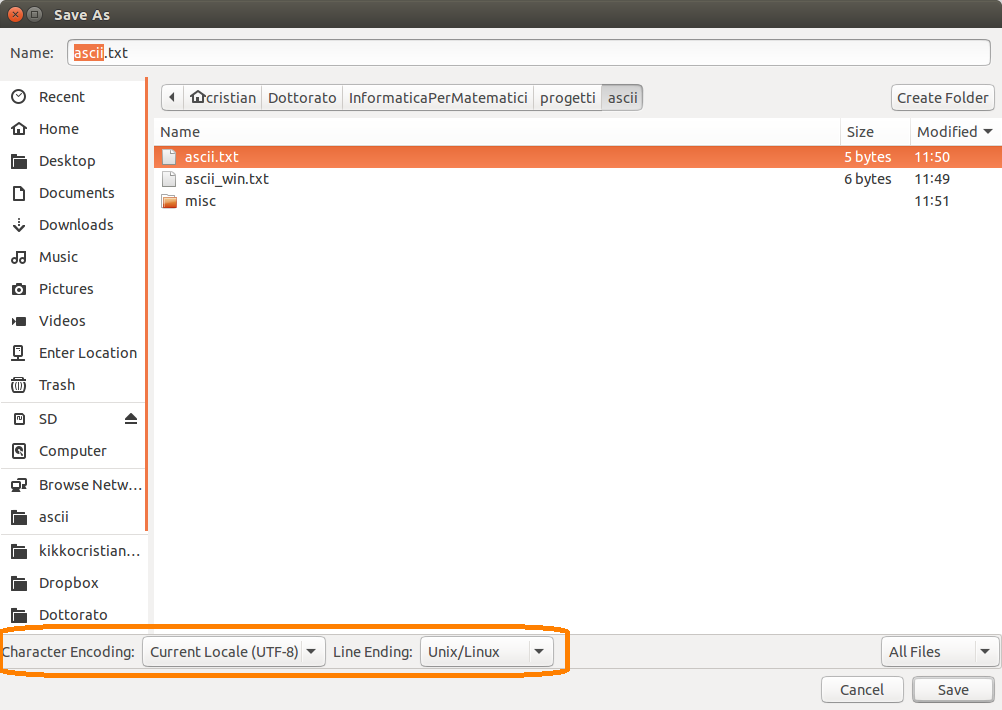 |
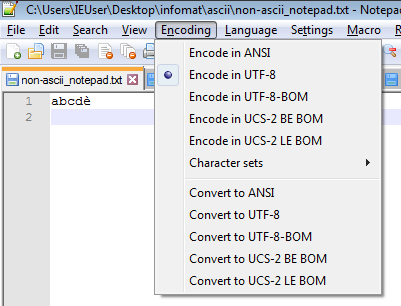 |
 |
|
Strumenti da linea di comando per convertire i terminatori di linea da Linux/Mac OS X a DOS/Windows (e viceversa)
Esistono svariati programmi per convertire i terminatori di riga tra i vari formati: da Linux o Mac OS X a DOS/Windows o “Mac classico”:
- dos2unix/unix2dos è un programma disponibile con una licenza libera e installabile su Linux, Mac e Windows. Un esempio di conversione dal formato *nix a DOS/Windows è il seguente:
$ unix2dos -n ascii.txt ascii_convertito_win.txt
unix2dos: converting file ascii.txt to file ascii_convertito_win.txt in DOS format ...-
tofrodos, ovvero todos e fromdos, programma del tutto simile al precedente. Su Ubuntu è disponibile nel pacchetto (installabile con
apt-geto dal Software Center)tofrodos. -
flip, un altro programma che converte tra i vari terminatori di riga. Anche in questo caso il codice sorgente è disponibile.
Se incontrate qualche caso strano questa domanda su StackOverflow approfondisce le differenze tra i file di testo su *nix e su Windows sia per quanto riguarda l’encoding che i terminatori di riga.
In conclusione
Per concludere, possiamo fare qualche conto relativo al file divina_win.txt.
$ ls -l divina_win.txt
-rw-rw-r-- 1 cristian cristian 5201 dic 15 14:39 divina_win.txtLa dimensione del file è 5201 bytes. Il comando file ci dice che usa i
terminatori di linea in formato Windows:
$ file divina_win.txt
divina_win.txt: UTF-8 Unicode text, with CRLF line terminatorsPossiamo usare il comando wc (word count)8 con l’opzione -l per contare
il numero di righe (ovver il numero di “a capo” del file):
$ wc -l divina_win.txt
136 divina_win.txtCon un’altra combinazione di comandi possiamo contare quanti sono i caratteri non-ASCII che compaiono in divina_win.txt:
grep -o -P "[\x80-\xFF]" divina_win.txt | # filtra tutti i caratteri non-ASCII e li stampa su una riga ciascuno
awk '!/^$/{a[$0]++}END{for (i in a)print i,a[i];}' | # conteggia le occorrenze di ogni carattere
awk '{sum+=$2} END {print sum}' # somma i conteggi
80Quindi ci sono \(80\) caratteri non-ASCII in divina_win.txt, in particolare sono i
seguenti:
ò 7 ó 1 è 10 é 8 « 8 ì 9 ù 8 » 8 à 17 ï 4
Se ora sottraiamo dalla dimensione del file (5001), il numero di caratteri terminatori di linea (ovvero il numero di linee per due) e i caratteri non-ASCII9 otteniamo: \(5001 - 136 \cdot 2 - 80 = 4849\).
Esattamente come nel caso precedente.
-
Gli encoding che includono ASCII nei loro primi 8 bit vengono detti ASCII compatibili (ASCII-compatible). ↩
-
la codifica di sistema dipende dal sistema operativo che state utilizzando e dalle impostazioni della lingua. I sistemi *nix generalmente utilizzano UTF-8, mentre Windows utilizza internamente UTF-16 low-endian. ↩
-
Con internazionalizzazione si intende la traduzione dei messaggi di un programma (come per esempio le voci di menu) in un’altra lingua. La localizzazione invece è il processo di adattamento di un software ad un contesto internazionale. Per esempio, l’internazionalizzazione consiste nel tradurre la voce di menu “Help” in “Aiuto” mentre la localizzazione è la possibilità di visualizzare, per esempio, delle lunghezze in metri invece che in iarde o piedi. ↩
-
Il paragrafo seguente è tratto da “The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) di Joel Spolsky ↩
-
v. la nota 3. ↩
-
Questa risposta su Stack Overflow chiarisce la differenza “encoding”, “character set” e “code page”? (in inglese) ↩
-
è possibile cambiare sia l’encoding di default che i terminatori da linea dal menu
Window > Preferences > General > Workspace. ↩ -
anche questo comando è disponibili su sistemi Windows e in un prossimo post vedremo come installarlo. ↩
-
ovvero, in questo caso tutti i caratteri non-ASCII sono rappresentati con 2 bytes e quindi sono contati due volte. ↩